
Pair Your Compilers At The ABI Café
May 5th, 2024

Not sure if your compilers have matching ABIs? Then put them through the ultimate compatibility crucible and pair them up on a shift at The ABI Café! Find out if your one true pairing fastcalls for each other or are just another slowburn disaster. (Maid outfits optional but recommended.)
I’m pretty sure I’ve tried to write some version of this article like 5 times over several years, but finally I got the right motivation, and I need to get some of this out of my head.
§1 Last Time On FFI Bugs
When last we left our heroine, she was sobbing uncontrollably about the absolutely disastrous state of affairs that is FFI, and how the best we’ve come up with is “everyone pretends to be C, even though C has the worst and wobbliest ABIs of all time”.
In that article I briefly discussed my own attempts at this, a tool called “abi-checker” which I’ve since renamed to abi-cafe.
To recap, abi-cafe was created in a feverish mania as I became increasingly obsessed with the disaster that was C’s technically-nonstandard-but-also-literally-used-in-standards __int128. Like sure there’s the whole intmax_t debacle, but that’s understandable. The truly unforgivable thing was that clang and gcc couldn’t reliably pass __int128 between each other. This of course meant that if Rust’s i128 wished to interoperate with them… it would always be wrong, because there was no correct answer.
Actually I’m telling this story a bit backward. Initially we definitely knew that Rust and Clang disagreed in at least one case on at least platform. Discussion of this issue was stalled out because people weren’t sure of the scope and nature of the problem. Which cases were broken? Who was right or wrong and needed to be fixed? What needed to be fixed? Did __int128 FFI work right on any platforms?
So I made abi-cafe, which let me describe a function signature in the abstract and generate code for the caller and callee, in Rust or C, and compile and link them together. Notably the generated code had both sides “report” the values they saw with callbacks, so the test harness could just run them and compare what each side reported.
I like this approach because it requires no actual knowledge of what the ABI “should” be and gets you very concrete error reports.
abi-cafe quickly helped me reproduce the __int128 issue between rustc and clang. I was also able to generate tons of different ways of passing it, so I quickly understood in what ways they diverged! Then on a lark I added support for gcc, and tested gcc_calls_clang and clang_calls_gcc to establish a baseline of “here’s it working” and… it… didn’t!? In fact all 3 compilers disagreed on x64 Linux!
This work quickly resulted in two important and clear conclusions:
-
Remember how I said
__int128was technically-nonstandard-but-also-literally-used-in-standards? Well those standards are the registers for Aarch64 (ARM64)! Specifically some low-level APIs for saving/restoring NEON (SIMD) registers are defined in terms of the__int128type, and so absolutely everyone agrees on the ABI of that type. As such, I was able to mark__int128FFI as safe/correct on that architecture! -
It was clear that the
__int128bug was rooted in LLVM, and that clang and rustc were inheriting the issue. Clang half-worked around it, while rustc just did whatever LLVM said. As a result, everyone disagreed! I am pleased to report that after much hand-wringing the issue has been resolved in LLVM, and that the latest rustc and clang releases interoperate with each other and gcc perfectly! I highly recommend the excellent article about this on Rust’s blog.
Congrats to everyone who worked on this, you’re the real MVPs!!!
§2 The Limits of abi-cafe 1.0
In the intervening time, abi-cafe was also used by the developers of rustc’s cranelift codegen backend to find at least one bug, which was super cool!
They suggested some more features it could have for checking more ABIs and I was in absolute agreement, but also at a bit of a loss for how to do them.
If you dig into the current main branch of abi-cafe you will see… A Big Fucking Mess. I had a specific problem to solve, and I wanted to fuck around with some ideas I had, and well, the whole thing was stuck in a bit of a local optima.
Most fundamentally, there were limits to the format for specifying a test that prevented enums, unions, and more complex type puns from being expressed.
As a result I’ve been at vaguely toying with the idea of abi-cafe 2.0 for quite a while, occasionally working through the theory and implementation of it, but needless to say it was all a bit exhausting and overwhelming, especially without the original motivation driving it forward.
But! My most recent burst of motivation has finally borne fruit, and I’ve finally gotten the full pipeline just barely working enough to compile and test rustc against itself with actual tagged unions! At this point I just need to fill in the C implementation and polish up some TODOs, although one of those TODOs in particular weighs heavily on my mind, and is the reason I wrote this article.
Or rather I was trying to explain the problem and solution I think I’ve worked out for the TODO, but, it’s so deep in the weeds that I accidentally wrote this entire article while trying to do so.
So… buckle up, we’ve got a lot of context to give!
And also keep in mind everything about abi-cafe 2.0 is EXTREMELY work-in-progress, and I only just barely got it kinda working, so, there’s still a fair bit of work to do!
§3 Why is abi-cafe
Ok so if the previous sections didn’t make it clear enough, I’ll just say it outright: ABIs are fucking Fake. Like, yes, they’re real. Lots of very important things rely on them. But they’re overwhelmingly unspecified and doomed to be “whatever the fuck some random compiler does”. People are constantly reverse-engineering them, often buggily. Other people get very mad you’re relying on them, often fruitlessly.
There are some specs, but they often don’t match the implementation, or are too vague to actually use. Also most importantly, the specs are often language-specific. This is fine and all for gcc and clang trying to interoperate, but Swift and Rust don’t have a type called “long long” and they somehow “do” C ABIs, so there’s absolutely Shenanigans happening even with well-regarded compilers. Cross-language FFI is definitionally all type puns, because the two languages don’t even have the same type systems or semantics!
When you explain this situation to people, they often get really upset, and invariably suggest that there should be some sort of abstract DSL for specifying ABIs, so that all the compilers can share and interoperate and everything will be great.
Listen, if this is you: Do it. It sounds impossible but I would love to have it. ABIs are so complicated and so variable and the inputs and outputs sound hellish but anything would be better than what we have now.
So anyway I’m a coward and abi-cafe is specifically not that. It has absolutely no idea how any ABI is implemented. It believes in the Existence of ABIs, and knows how to make things that Might survive a crossing through the blind eternities of a function call, and it knows how to check that the trip was a success.
So if you do ever write that ABI DSL, abi-cafe will pair wonderfully with it as a way to test that a compiler that uses it continues to produce the same results (or better).
§4 What Does It Mean For Compilers To Agree?
Earlier I mentioned that abi-cafe works by having both sides “report” the values they saw with callbacks. But what does that mean, and how do we determine that the values are “right”?
To investigate this question, we’re going to look at a bunch of examples of code/types we want to have interoperate between Rust and C(++), with little split code sections like this:
some_rust
some_more_rust some_c
some_more_c
§4.1 The Base Case: Primitives
Primitives like integers and floats are the indivisible atoms of a language. Let’s start with a type pun so boring, many would balk at the suggestion that it even is one:
u32 uint32_t
I think we can all agree that these have to work or nothing will. That said, there’s a ton of things to get right, as discussed in a previous article on ABIs. Things can definitely go wrong here, as we saw with the whole __int128 debacle!
Currently abi-cafe asks both languages to copy a primitive’s bytes into a buffer to prove they knows its value. If both sides agree, well, clearly the value was passed properly! This is a pretty good heuristic for the platforms and languages I care about, because finding a primitive’s location (and size) in memory is basically the only challenge.
So for instance, if we were interested in checking i32 interop we’d generate code like this, with Rust being the “caller” that produces the values and C being the “callee” that receives them. We then use some API for reporting values (sending their bytes to the test harness). For the purposes of the article, we’ll call that API write_val:
fn run_tests() {
let x: i32 = 0x0403_0201;
write_val(&x);
let y: i32 = 0x1413_1211;
write_val(&y);
test1(x, y);
} void test1(int32_t x, int32_t y) {
write_val(&x);
write_val(&y);
}
If the harness sees both sides reported two values, and the bytes of each value are the same on both sides, then we’re pretty confident the two i32s were passed properly here! Generate a lot more cases to stress all the weird corners or register allocation and alignment and suddenly you’re pretty confident the two languages interoperate completely.
⚠️ Something subtle but important here is that we’re relying on both sides agreeing on the order to report the values in. We can guarantee this in abi-cafe because we’re generating both sides from an abstract definition. In fact the test harness can theoretically know exactly what the write_val results should be before even running the test (although this requires assuming/knowing ABI details and we want to avoid that). This will become a harder problem with more subtle implications as we go on.
§4.1.1 An Aside: Picking Values For Primitives
You may have noticed I picked kind of weird example values there: 0x0403_0201 and 0x1413_1211. I call these “graffiti values” because each byte has been tagged with metadata of where it’s supposed to be. If we break up each value into its bytes, we get a nice little sequence:
x = [04, 03, 02, 01]
y = [14, 13, 12, 11]The idea here is that the high nibble of the byte is tagged with the index of the value (x = 0, y = 1), and the low nibble is indexed with the tag of the byte. The are several benefits to this system!
First off, basically every byte is unique up to multiples of 16, so it’s hard to “get lucky” when there’s an ABI error, as opposed to if there was lots of 0x0000 or 0xFFFF. I initially was providing “distinct” values manually and I quickly determined that no we should just let the computer do that.
Second, when there is an error, it’s often relatively easy to see what went wrong. For instance, let’s say the test harness reports and error and shows us the following:
gcc_calls_rustc mismatch on test1 arg1:
gcc: [13, 12, 11, 10]
rustc: [11, 10, 24, 23]
The gcc value looks normal: all the high nibbles are equal, and they appear in the order your expect. The rustc value is definitely messed up though: we can see that half of its bytes are from arg1, but the other half are from arg2! Also we didn’t get an error on arg0. Together these facts point to rustc expecting the value to be more aligned (and therefore padded).
We don’t know which compiler is right here, but we know they disagree, and can now do the social work that is getting people to agree on the ABI (or just concede that gcc is the boss and change rustc to match).
§4.1.2 An Aside: Primitive Semantic Checking
The above implementation is technically missing an opportunity to check that the languages agree on the semantics of the values. Even if they find the same bytes they could theoretically diverge on things like signedness, endianess, twos complement, which values of bool are “true” vs “false”, and so on.
I haven’t implemented this and I’m not sure I ever will, but one way to approach this would be to introduce a challenge-response protocol to the process. For instance, if you have one side add a number to the value, and require the other side to subtract it back out, then you’re pretty confident they agree on at least endianess (and I’m sure you could come up with challenges for any other properties you care about):
fn run_tests() {
let mut x: i32 = 0x0403_0201;
write_val(&x);
x += 0x1234_5678;
let mut y: i32 = 0x1413_1211;
write_val(&y);
y += 0xABCD_EF12;
test1(x, y);
} void test1(int32_t x, int32_t y) {
x -= 0x12345678;
write_val(&x);
y -= 0xABCDEF12;
write_val(&y);
}
§4.2 The Inductive Case: Composite Types
Structs like this require us to think a little bit harder about what it means for two languages to agree on values:
#[repr(C)]
struct Simple {
flags: u8;
val: u32;
} struct Simple {
uint8_t flags;
uint32_t val;
};
We can’t just copy the bytes of the entire structs, because they’re liable to contain padding which is allowed to differ between the two sides of the boundary. The only parts we can and should care about are the primitive fields that form the “leaves” of a (potentially nested) composite type.
We already know how to analyze those, so the only thing we need to introduce here is an understanding of how to access each subfield, and a new kind of delimiter for “end of function argument” for easier bookkeeping and error reporting. So we add an end_arg() callback and generate this kind of code:
fn run_tests() {
let x = Simple {
flags: true,
val: 0x1413_1211,
};
write_val(&x.flags);
write_val(&x.val);
end_arg();
let y = Simple {
flags: false,
val: 0x3433_3231,
};
write_val(&y.flags);
write_val(&y.val);
end_arg();
test1(x, y);
} void test1(Simple x, Simple y) {
write_val(&x.flags);
write_val(&x.val);
end_arg();
write_val(&y.flags);
write_val(&y.val);
end_arg();
}
⚠️ Once again we find ourselves relying on ordering, but once again this is fine because the test harness that generates the code gets to pick a “canonical” ordering, and both sides agree on the number of primitive fields to report. There are two ways of looking at what we’re doing:
-
We’re essentially generating a fully inlined implementation of
#[derive(Debug)]for each function argument, and then checking that both sides produced the same printout. Just visiting every field, how hard could that be? -
We’re generating an in-order tree traversal of the primitives in a composite type.
What tree am I talking about? Well, look at this:
arg0: MyType {
some_val: MyInnerType {
count: u32,
down: u64,
engaged: bool,
}
some_other_vals: MyArray(
[Vec3 {
x: f32,
y: f32,
}; 2]
)
}That right there is a damn tree, as demonstrated through hasty paint diagrams:
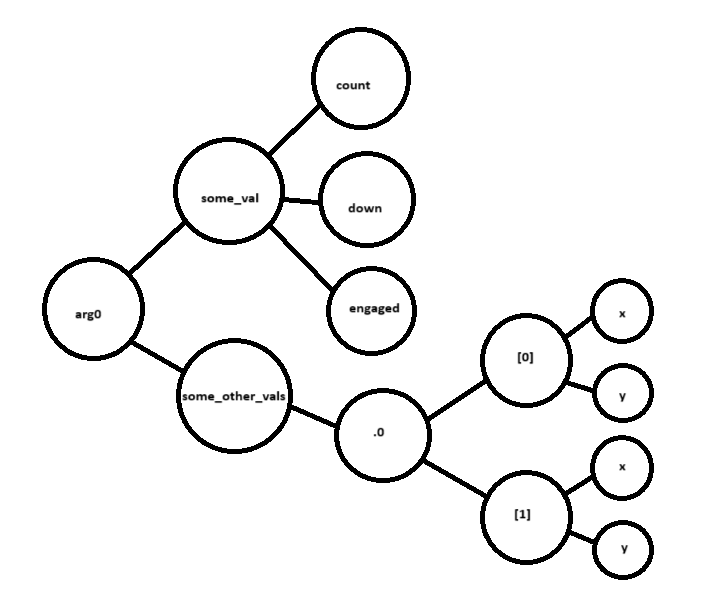
Consider this some Really Fucking Important Foreshadowing.
§4.3 Tagged Unions: I Guess Alright?
It’s time for me to bring up my favourite Rust RFC: 2195-really-tagged-unions, wherein I let you put repr(C) and repr(u8) on Rust tagged unions to get a guaranteed C(++)-compatible layout. Here we show the more pleasant C++ layout:
#[repr(u8)]
enum TaggedUnion {
Val1(u32),
Val2(u32),
Val3(u32, bool)
Empty1,
Empty2,
} enum class TaggedUnion_Tag: uint8_t {
Val1, Val2, Val3, Empty1, Empty2
};
union TaggedUnion {
struct {
TaggedUnion_Tag tag;
uint32_t val0;
} Val1;
struct {
TaggedUnion_Tag tag;
uint32_t val0;
} Val2;
struct {
TaggedUnion_Tag tag;
uint32_t val0;
bool val1;
} Val3;
struct {
TaggedUnion_Tag tag;
} Empty1;
struct {
TaggedUnion_Tag tag;
} Empty2;
};
This is absolutely a real thing, and cbindgen knows how to generate it, and FireFox uses it in production (I don’t think I can stable-link that file’s contents, search for “union RasterSpace”).
This case poses a few problems.
The first problem is a totally artificial limitation of abi-cafe 1.0: because I opted for describing function signatures with example values, any type with cases that won’t show up in every value is fundamentally inexpressible. If I give the value TaggedUnion::Val1(u32(100)), that fundamentally fails to describe Val2 and Empty. This limitation is the crux of why abi-cafe 2.0 had to be basically a complete rewrite. I need a proper type system to describe the shape of a type independently from its values!
The second problem is that “selecting” a value is now a much more dramatic problem. Before the only decision worth making was what number to put in an integer. Now we need to pick which case is “interesting”, and that can change the number and types of fields to report. But that’s ok, because both sides will agree! You can totally #[derive(Debug)] on a Rust tagged union, so we know we can report the fields of each case properly with a bit of elbow grease.
The last problem is that “reporting” all the values is suddenly less well defined. Previously we hand-waived the matter of “semantics” and said that if both sides agree on the primitives, we’re all good. But here Val1 and Val2 are indistinguishable by that metric. Empty1 and Empty2 are even worse, with no values to report at all!
In this case we kind of get lucky, because the C-compatible layout forces the value of the tag to become defined as a u8, so we can introduce that as a “field” that needs to be reported whenever you report a tagged union’s values. If we were testing Rust’s own ABI we would have to make up a numbering system for the tags.
None of this is a dealbreaker, but it’s certainly a lot more annoying work. Probably we end up with something like:
fn run_tests() {
let x = TaggedUnion::Val3(16, true);
match &x {
TaggedUnion::Val1(val0) => {
write_val(0u8);
write_val(val0);
}
TaggedUnion::Val2(val0) => {
write_val(1u8);
write_val(val0);
}
TaggedUnion::Val3(val0, val1) => {
write_val(2u8);
write_val(val0);
write_val(val1);
}
TaggedUnion::Empty1 => {
write_val(3u8);
}
TaggedUnion::Empty2 => {
write_val(4u8);
}
}
end_arg();
test1(x);
}§4.4 Untagged Unions: FUCK OK
Hey we just did tagged unions so c-like untagged unions are probably the same and… well. They’re not! All of our foreshadowing has come to roost! Let’s review:
We’re essentially generating a fully inlined implementation of
#[derive(Debug)]for each function argument.
You can totally
#[derive(Debug)]on a Rust tagged union, so we know we can report the fields of each case properly with a bit of elbow grease.
You know what you can’t #[derive(Debug)] on? A c-like untagged union. Just absolutely not, no way. There’s no way for the receiver of the value to know which case you should be in, and trying to report all the cases would generate random padding-like garbage.
But we’re not doomed! We can cheat with more foreshadowing!
In fact the test harness can theoretically know exactly what the write_val results should be before even running the test (although this requires assuming/knowing ABI details and we want to avoid that). This will become a harder problem with more subtle implications as we go on.
The subtle implications, they are here! We don’t need to generate proper match statements for untagged unions, because the test harness generating the code already knows which case every single value is. So for tagged unions, instead of actually generating a full match it could generate this:
// I am a smart test harness that knows what case it will be
let TaggedUnion::Val1(val0) = &arg0 else {
panic!("arg0 was supposed to be Val1, but wasn't!");
}
write_val(0u8);
write_val(val0);Which for an untagged union becomes this even simpler expression:
// I am a smart test harness that knows what case it will be
write_val(&arg0.Val1.0);Ok so we’re still trucking, but now we definitely need a central system that knows the values of everything, and can’t just pick them on the fly when generating the caller. How to express this in code is a bit brain-melty, but we can appeal to our last bit of foreshadowing:
We’re generating an in-order tree traversal of the primitives in a composite.
We’re still doing this but at some of the nodes we have to pick only one of the branches to take (the enum variant to select). There’s lots of ways to encode tree-traversals, like numbering the branches of each node, and creating a sequence of the branches to follow. I’m sure we can figure something out.
§4.5 REAL PUNS: REAL PAIN
Now to really fuck my whole life up with overly ambitious ideas. It’s time for foreshadowing part two: fuck your life for real!
Now we need to pick which case is “interesting”, and that can change the number and types of fields to report. But that’s ok, because both sides will agree!
There’s lots of ways to encode tree-traversals, like numbering the branches of each node, and creating a sequence of the branches to follow. I’m sure we can figure something out.
WHAT IF THE TWO LANGUAGES DIDN’T AGREE ON THE NUMBER AND STRUCTURE OF THE FIELDS?
Let’s start off really simple, and work our way up to the real warcrimes.
§4.5.1 Transparent Primitives: Ok!
A cute little feature of Rust is repr(transparent), which lets you wrap primitive types in a new type so you can get stronger type checking on “these are the array indices for this specific kind of data structure” or “these are meters”, but critically you can keep them 100% abi-compatible with a bare primitive:
#[repr(transparent)]
struct Meters(u32); #define Meters uint32_t
For example, 32-bit x86 Linux has a C ABI where a primitive and a struct wrapping a primitive get passed differently, so this attribute is significant, and we definitely want to test that it works right!
But suddenly we have introduced a non-trivial divergence in the structure of our types. In Rust there is an extra layer of composite to peel away, while in C the primitive is right there.
In our nice naive world of “just report the primitives in order” this is actually totally fine, we don’t care about how many composites are in the way. But…
There’s lots of ways to encode tree-traversals, like numbering the branches of each node, and creating a sequence of the branches to follow. I’m sure we can figure something out.
This is now a bit harder to think about, eh? One of the trees has an extra node in it. Thankfully it has to be a node with one child, so you can imagine a few ways to handle this automatically, but the cracks are really starting to form!
§4.5.2 Option Optimization: Uhhh
Here’s another fan favourite: the guaranteed Optional reference optimization in Rust:
enum Option<T> {
Some(T)
None,
}
Option::<&u64> uint64_t*
Not only is Option<&T> guaranteed to be the same size and layout as a pointer, but it’s even guaranteed that None will be null, and that it will be ABI compatible with C pointers.
Also note: this enum doesn’t have a repr annotation on it, this is a for reals native Rust enum layout.
In the Some case things are easy enough, but in the None case… what are we supposed to do? I’m not sure how to handle this other than absolutely special-casing the fuck out of it! Alas!
§4.5.3 CRIMES CRIMES CRIMES
Look I know I just finished explaining repr(transparent) and also how __int128 is a nightmare buuuut maybe you think you can get away with this hot garbage:
#[repr(C)]
struct SyntheticU128 {
high: u64,
low: u64,
} __uint128
Sure would be nice to be able to test on which platforms and in which situations that kind of thing would work, but oh god now the “trees” we want consistent traversals for are becoming an absolute mess.
Hey you know what, why not fuck me up with this:
#[repr(C)]
struct Pair {
x: u32,
y: u32,
}
#[repr(C)]
struct Triple {
pair: Pair,
z: u32,
} struct AltPair {
uint32_t y;
uint32_t z;
};
struct AltTriple {
uint32_t x;
AltPair pair;
};
Or this:
struct Vec3 {
x: f32,
y: f32,
z: f32,
} struct Vec3 {
float vals[3];
};
I wanna be able to test all these!!!
Trying to build a system that can properly synchronize all these different type puns into a single coherent “traversal” where the values can be properly compares is the big “TODO” that got me to write this article.
There is a certain intuition to how you can synchronize the trees properly, and boy howdy this article was supposed to elucidate that intuition, but it’s so long and I’ve absolutely fried my brain writing this much, so I think I’m gonna just mention where I’m at and wrap it up for now.
§5 The Heart Of abi-cafe 2.0: kdl-script
Ok so abi-cafe 1.0 fell over by the time we got to tagged unions, because we needed a way to talk about the structure of types in a way that single values couldn’t. The code for ABI backends (generating Rust and C code) for the definitions was also already an unmaintainable mess, so I wanted to have more of an agnostic framework that handles a lot of the details, so that the backends could focus on just the specifics of their languages.
This is a type system and a compiler. I’m describing a normal compiler. I fear and loathe normal compilers, even though I keep making and working on them.
One of the biggest hurdles for me was good parsing and error handling. We all know the old gag: you take a compilers course in university, and they spend 90% of the course talking about LR(1) grammars and then frantically at the end go “uhh oh and you should make the compiler actually do things”. Except also everything they teach you about parsers is bad and wrong too.
Then I got shown KDL, whose canonical implementation is written in Rust and which looks a lot like Rust code:
package {
name "my-pkg"
version "1.2.3"
dependencies {
// Nodes can have standalone values as well as
// key/value pairs.
lodash "^3.2.1" optional=true alias="underscore"
}
numbers {
x 123
y 456
}
}
Wouldn’t it be funny if I made a programming language where every program was a valid KDL document? And thus kdl-script was born!
@derive "Display"
struct "Point" {
x "f64"
y "f64"
}
fn "main" {
outputs { _ "f64"; }
let "pt1" "Point" {
x 1.0
y 2.0
}
let "pt2" "Point" {
x 10.0
y 20.0
}
let "sum" "add:" "pt1" "pt2"
print "sum"
return "+:" "sum.x" "sum.y"
}
fn "add" {
inputs { a "Point"; b "Point"; }
outputs { _ "Point"; }
return "Point" {
x "+:" "a.x" "b.x"
y "+:" "a.y" "b.y"
}
}
Well, ok that’s the shitpost version with actual function bodies. kdl-script for its true purpose ends up looking more like this:
// Types
struct "Simple" {
a "i32"
}
alias "Simple2" "Simple"
struct "Complex" {
elems "[Simple;10]"
val "Simple2"
opaque "ptr"
flag "bool"
}
enum "ErrorCode" {
Ok 0
FileNotFound 1
Bad -3
}
tagged "MyResult" {
Ok { _ "[u32;3]"; }
Err { _ "ErrorCode"; }
}
tagged "MyDeepResult" {
Ok { _ "MyResult"; }
FileNotFound { x "bool"; y "Simple"; }
}
// Function signatures we want to test
fn "func1" {
inputs { a "Complex"; b "Simple"; }
outputs { out "i32"; }
}
fn "enumtime" {
inputs {
a "&MyResult"
b "MyDeepResult"
c "[&ErrorCode;4]"
}
}
It’s all signatures, no bodies. Because at the end of the day, generating the bodies is the problem of abi-cafe’s ABI backends. And I’m happy to report, the kdl-script compiler works, and I’ve got the rust backend fully implemented!
…except for maybe some overzealous outparam support that I don’t really care about anymore. Oh and the whole “complex type pun tree traversal” thing this whole article is all about.
Oh right I haven’t even shown the feature of kdl-script that makes complex puns a possibility: pun types!
pun "MetersU32" {
lang "rust" {
@ "#[repr(transparent)]"
struct "MetersU32" {
a "u32"
}
}
lang "c" "cpp" {
alias "MetersU32" "u32"
}
}
kdl-script has a first-class notion of basically “a type wrapped in an ifdef switch statement”. This allows us to declare a single function signature, but make different languages/compilers interpret in different ways.
I fucking love it, but it’s an absolute nightmare to think about because IT MAKES THE TREES DIFFERENT SHAPES.
BUT I SWEAR, YOU CAN MAKE IT MAKE SENSE.
TRUST ME.
OK I NEED. TO GO. TO BED. I HAVE BEEN WRITING THIS ALL DAY. HAVE A GOOD NIGHT.